
广东外语外贸大学任函主持完成的全国科技名词委科研项目“基于深度学习的政治领域双语术语库自动构建研究”(项目批准号为:YB2019013),最终成果为政治领域多语种术语资源库、计算机软件《双语术语库检索系统》和系列论文《面向语言智能教学系统的领域知识图谱构建》等。课题组成员有:刘伍颖、任亚峰、章宜华、夏立新、冯文贺、吕晨、彭琼、万菁。
一 研究的目的和意义
中国的政治术语有其特点,它一般与中国的文化和社会环境相关,在其它语言文化中缺乏具有对等概念的术语。中国的政治术语反映了中国在特定时期的内政外交、经济文化等各方面的状况,具有鲜明的民族和时代特色。
语言是文化的载体,中国的政治术语正是中国几千年深厚文化的具体反映。为获取汉语文本中的政治术语,首要问题就是准确理解汉语词汇的文化内涵,并在翻译语言的文化中找到合理投射。然而,这对术语审查人员提出了非常高的要求,在具体实践中往往难以满足,高质量的双语术语语料也就难以保证。
本项目在研究中国政治术语的语言特点的基础上,分析了领域双语术语对的自动获取方法,并建立了一个政治领域多语种术语资源库及展示系统。同时,在社会文本分析、知识图谱构建等领域对研究内容中的模型、方法进行了验证。本项目研究的意义在于:①深化与拓展双语对齐分析技术。双语篇章单元对齐技术能够较为准确的双语对齐片断,孪生神经网络等深度学习模型的应用则能够提供更好的抽取性能;②解决制约双语术语对抽取的瓶颈问题,推动大规模政治领域双语术语资源库的自动构建,促进双语术语资源在计算机辅助翻译、机器翻译、词典编纂等领域的研究与应用。
二 成果的主要内容
(1)政治领域多语种术语数据库。本项目建立了一个面向政治领域的多语种术语数据库,并构建了相应的展示系统。本项目的语料来源于多语种政府工作报告、政策性文件及著作,以及官方媒体(人民日报中英文版、环球时报中英文版等)的多语言文本等。政府工作报告为权威的政治文件,其术语规范性具有很好的保障;而人民日报、环球时报也均为权威报纸,其中文文本的英文翻译结果的质量较高,也能够保证术语的规范性和权威性。同时,本项目还利用了已有非通用语言资源进行数据库构建,包括汉语和越南语、印尼语两种语言的双语对齐文本。
表1 多语种术语数据库统计结果
| 术语对类型 | 数量 | 比例 |
| 汉-英 | 26704 | 85.8% |
| 汉-法 | 1190 | 3.82% |
| 汉-日 | 1056 | 3.39% |
| 汉-韩 | 783 | 2.52% |
| 汉-越 | 715 | 2.30% |
| 汉-印尼 | 677 | 2.18% |
| 总数 | 31125 | 100% |
本项目抽取的多语种术语对涵盖7种语言,包括汉语、英语、法语、日语、韩语、越南语和印尼语,每个术语对均包括一个汉语术语和一个对应的外语术语。表1展示了术语库的统计结果。从数量上看,汉-英术语对比例最高,原因在于汉英双语文本远多于其它语言对文本。从总数上看,共抽取30000余条术语对,超额完成了最初设定的20000条汉-英术语对的任务目标。
(2)双语术语自动抽取系统。双语术语抽取一般利用词对齐或句对齐信息,其问题在于词汇及短语边界识别存在歧义,导致对齐性能不理想,句对齐则粒度较粗,影响术语抽取的性能。本项目采用基本篇章单元为对齐目标,从基本篇章单元中获取语义一致的对齐术语,这有助于改进文本对齐性能,提高术语库构建质量。
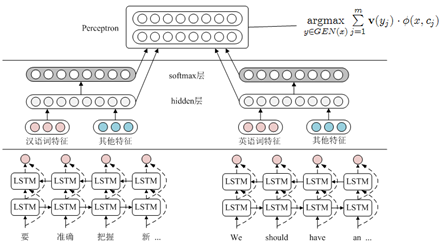
图1 双语篇章分析系统
前期工作已经建立了一个面向汉语的篇章结构分析模型。本项目对该模型进行了改进,使其能够进行双语篇章结构分析对齐工作。具体来说,首先对汉语文本进行基本篇章单元分析,然后利用分析结果指导其它语言文本的基本篇章单元分析。模型的代价函数为两个基本篇章单元词汇一致度,超过阈值则认为基本篇章单元对齐。一致度的计算方法是汉语词汇和其它语种词汇的交集与它们的并集之比,交集是指两个词互为翻译。图1展示了模型结构。
术语抽取和对齐利用基本篇章单元分析结果。首先实现了汉语术语抽取,该任务是一个典型的序列标注任务,采用双向LSTM神经网络模型建立模型。在前期工作中,已根据《常用政治名词术语词典》、《汉英中国政治术语词典》等词典中的汉语及英语政治术语建立了一个术语集合,并在政府工作报告、人民日报中英文版、环球时报中英文版等资源中搜索包含该词的句子,以此构建了一个术语抽取的训练集,训练集中的每个实例包含一个汉语及英语的政治术语对,以及包含该词的句子。这一数据作为模型的训练数据。在对齐阶段,利用一致度进行对齐,仍然采用图1所示的对齐分析系统。
(3)政治领域多语种术语数据库展示系统。本项目建立了一个多语种术语数据库展示系统,数据来源于已抽取的政治领域多语种术语对。
系统功能主要包括术语浏览、术语检索、用户管理等,如图2-5所示。其中,术语浏览功能可查看数据库中的全部术语,术语检索功能可利用关键词搜索数据库中的术语。检索功能提供了部分检索、模糊检索和跨语言检索功能,其中:部分检索是指可以检索术语的一部分,如要查询“社会主义核心价值观”,可输入“核心价值”进行检索;模糊检索是指可以利用词汇的一部分进行检索,如要检索“丝绸之路经济带”,但不清楚经济一词在英文中是采用名词还是形容词形式,则可以利用原形“economy”进行检索;跨语言检索是指输入一种语言的词汇,可以检索其它语种的对应术语,例如输入“belt”,可以检索到“一带一路”、“长江经济带”等词汇。
图2 用户管理
图3 系统介绍

图4 术语浏览
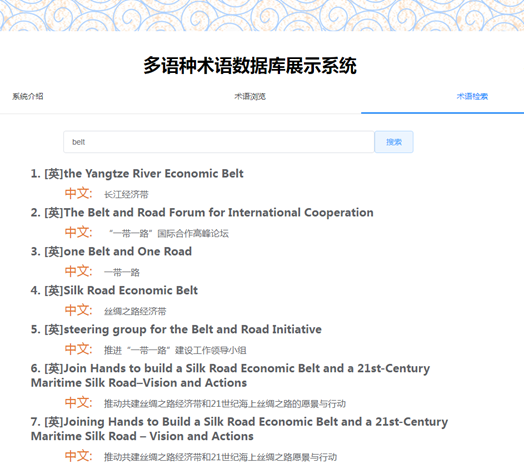
图5 术语检索
(4)领域知识图谱构建。本项目利用项目建立的术语抽取模型,实现了一个面向对外汉语教学的领域知识图谱,数据来源包括教学大纲、教案、教材、试题库,以及百度百科和维基百科语料。节点包括语言知识、汉语学习与汉语教学三部分。语言知识本体包括语言要素和文化要素两个方面。语言要素即语言基本知识,包括汉字、词汇、句法、语义。文化要素即语言所承载的文化内涵,包括传统文化、社会心理、民族特色、语言交际等。汉语学习本体包括言语技能和学习技能。言语技能即学习者的语言能力,包括听、说、读、写四个方面的概念;学习技能即学习者学习语言的能力,包括智力水平、学习方法以及学习管理三个方面的概念。汉语教学本体包括教学原则和教学实践。教学原则即教学过程中的基本内容和要求,包括教学目标、对象、类型、任务、效果等方面的概念;教学实践即实际教学过程中包含的内容、方法和经验,包括教学大纲、教案、教学进度、教学测试与评估等方面的概念。
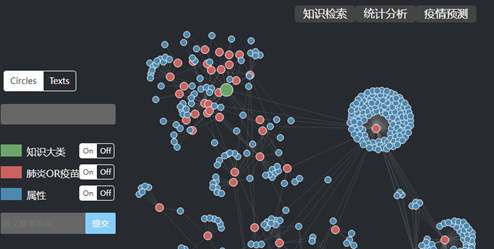
图6 新冠疫苗知识图谱
本项目还利用上述方法建立了一个新冠疫苗知识图谱。该知识图谱为国内首个以新冠疫苗为主要内容的知识集合,其中包括疫苗类型、性质、功能、生产、接种等各类知识。为此,抽取了5000余条术语,并建立了一个基于该知识图谱的领域问答系统。
(5)社会文本分析。情绪原因分析是社会文本分析研究的重要内容之一。传统分析模型利用标点符号将句子划分成若干子句,然后分别判断子句是否为原因句,然而原因可能由多个子句构成,采用上述方法难以抽取完整的原因句。事实上,原因句往往包含在基本篇章单元中,为此,本研究采用了篇章分析模型,将句子划分为若干基本篇章单元,然后再识别每个单元是否为原因。模型结构如图7所示。
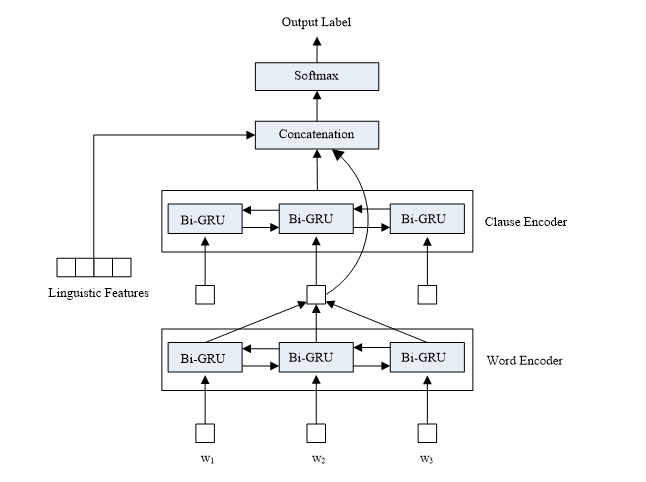
图7 情绪原因分析模型
三 成果的主要价值
从学术价值上看,本项目的开展将有助于解决制约双语术语对抽取的瓶颈问题,推动大规模政治领域双语术语资源库的自动构建。
从应用价值上看,本项目的开展将促进多语种术语资源在计算机辅助翻译、机器翻译、词典编纂等领域的研究与应用。
从社会影响和效益上看,本项目语种覆盖RCEP协议中大多数国家的官方语言,能够为政府部门、非政府机构和个人在RCEP框架下进行沟通提供有效的翻译资源与平台。